

We develop and integrate AI into the scientific process, leveraging its potential to overcome human cognitive limitations in traditional research. Our work focuses on AI for discovery of scientific models—such as equation and algorithm discovery—and AI for optimizing experiments. Additionally, we develop multi-agent systems capable of interacting with scientific data, fostering more autonomous and scalable approaches to empirical research.
AI is transforming every domain of scientific inquiry, but accelerating discovery requires more than just AI—we need computational infrastructure that enables AI to automate scientific practices. In our research group, we develop tools for automated data collection, documentation, and interfaces that facilitate collaboration between human and AI scientists. Central to this effort is AutoRA, a declarative programming language in Python that allows researchers to define empirical research problems and specify the AI methods they wish to employ in solving them.
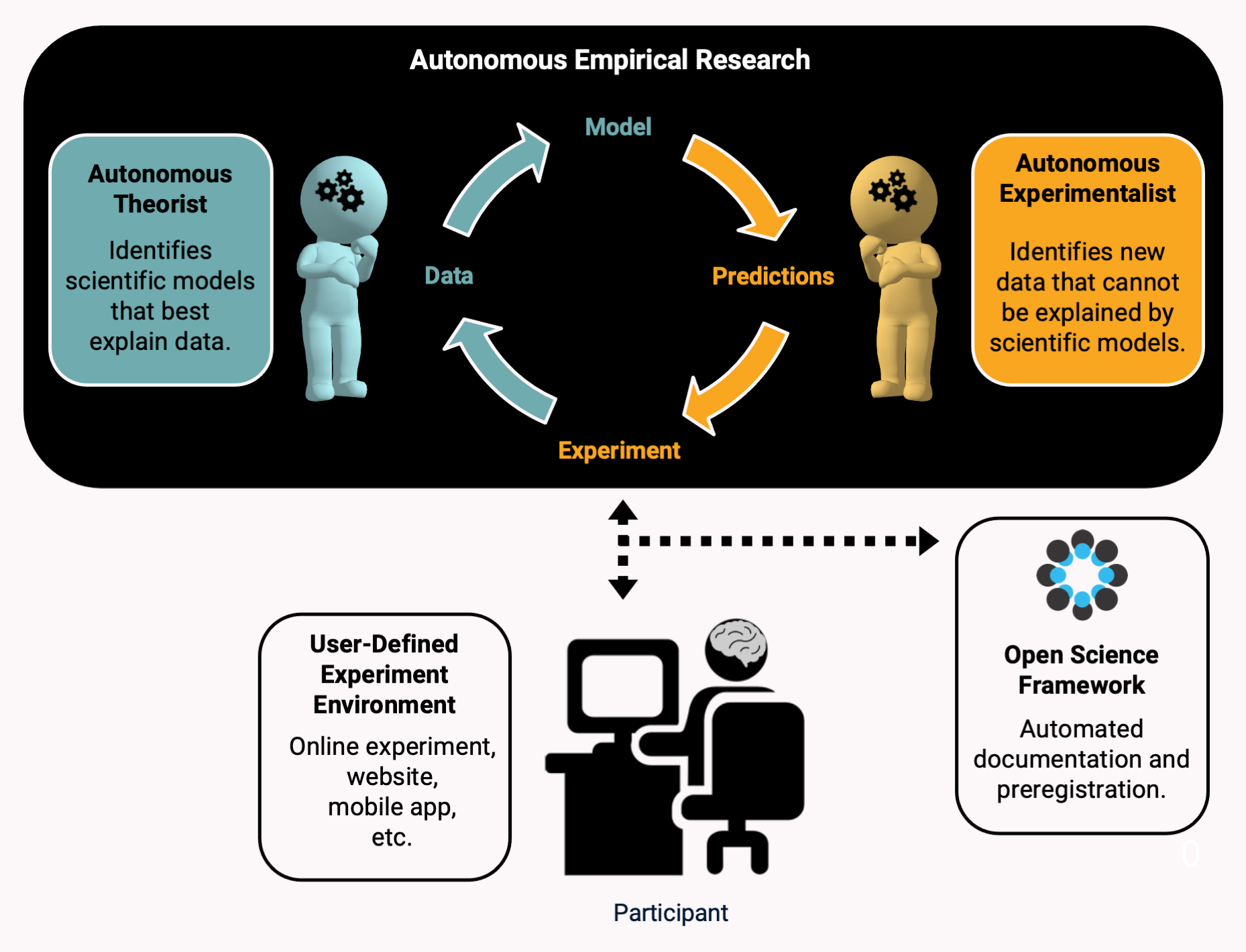
Automated scientific discovery can be implemented in AutoRA, e.g., as a dynamic interplay between two artificial agents. The first agent, a theorist, relies on existing data to construct computational models by linking experimental conditions to dependent measures. The second agent, an experimentalist, designs follow-up experiments to refine and validate models generated by the theorist. Together, these
agents enable a closed-loop scientific discovery process.
Automating scientific practice raises a fundamental question: how should we automate science? In our research group, we study the scientific process itself through computational metascience. This includes developing better metrics to assess the success of automated scientific discovery and evaluating general strategies for idea generation, model exploration, and experimentation.